R ile Çoklu Regresyon Analizi: (Wooldridge Örnekleri)
Çoklu regresyon analizinde bir çok fonksiyonel form kullanılabilir ve bu bize daha fazla esneklik sağlar.
Önceki bölümlerde basit regresyon modeli ele alındı ancak basit regresyon açıklamak istediğimiz bağımlı değişkeni sadece bir bağımsız değişkenle açıklamaya çalıştığı için ceteris paribus (diğer herşey sabitken) varsayımını ihlal etmesi çok olasıydı. Üstelik bu bağımlı değişkeni açıklayan ve bağımlı değişkenin üzerinde de etkisi olan başka bir değişken olmaması olasılığı da çok düşüktü. Çoklu regresyon modeli tahmincimize başka değişkenler ekleyerek y nin üzerindeki varyasyonu daha fazla açıklama şansı doğuracaktır. Çoklu regresyon modelinin bir diğer avantajı bağımsız değişkenin derecelerini arttırarak parametrelerde doğrusal olmasına rağmen doğrusal olmayan fonksiyonlar elde edilebilir ve daha iyi bir açıklayıcı elde edilebilir.
İki bağımsız değişkenli model
Bu bölümün Wooldridge kitabınızda bulunan ilk örnek maaş (wage) bağımlı değişkenin iki bağımsız değişkenle açıklamaya çalıştığımız model. Bu modeli tekrar hatırlayalım.
Burada
Basit regresyon bölümünde kurduğumuz modeli dikkate alalım
Ancak hala yapmamız gereken önemli varsayımlar mevcut. Bu ikili değişken modelinin bize kattığı artık
Anlaşıldığı gibi, bu bölüm atlanan (gözlemlenemeyen) değişken sapmasını (“omitted variable bias”) da belli bir ölçüde açıklayacaktır. Çoklu regresyon modelini kullanmamızın bir diğer nedeni de örneğimizden anlaşılacağı üzere gözlemlenemeyen (atlanan) değişken sapmasını ortadan kaldırabilmektir.
Çoklu regresyonun ana fikirlerinden biri, bu ihmal edilen değişkenler hakkında verimiz varsa, onları ek regresörler olarak modele dahil edebilmek ve böylece diğer değişkenleri (deneyim (
Alternatif olarak, eğer biri nedensel çıkarımlar değil de tahminle ilgileniyorsa, çoklu regresyon modeli, tek bir regresör kullanılarak yapılan tahminleri geliştirmek için birden fazla değişkenin regresör olarak kullanılmasını mümkün kılar. Bu konuya ilerideki kesimlerde daha detaylı olarak geri döneceğiz.
Kitabınızda sunulan bir diğer iki bağımsız değişkenli regresyon örneği, öğrenci başına yapılan harcamanın (
İki bağımsız değişkenli çoklu regresyon modelini genel bir şekilde yazarsak,
Burada,
İki açıklayıcı değişkenli regresyon modelinin kitabınızdaki bir diğer örneği, doğrusal regresyon modelinin fonksiyonel olarak yazılabildiğini göstermek için verilmiştir. Ailenin tüketimini, ailenin gelirinin ikinci dereceden (quadratic) bir fonksiyonu olarak gösterirsek
k bağımsız değişkenli model
Çoklu regresyon modeli olarak adlandırılabilir.
Çoklu regresyon modelinin temel varsayımını hatırlayalım.
Örnek3.1 Kolej Gpa’sının Belirleyicileri
- ödeviniz olarak da verdiğim kolej Gpa’sının belirleyicileri örneğinin datasını indirelim ve içinde bulunan değişkenlere göz atalım.
library(wooldridge)
data(gpa1)
library(rmarkdown)
paged_table(gpa1)
age <int> | soph <int> | junior <int> | senior <int> | senior5 <int> | male <int> | campus <int> | business <int> | engineer <int> | ||
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 21 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | |
| 2 | 21 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | |
| 3 | 20 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | |
| 4 | 19 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | |
| 5 | 20 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | |
| 6 | 20 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 0 | |
| 7 | 22 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | |
| 8 | 22 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | |
| 9 | 22 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | |
| 10 | 19 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
Örnek için kullanacağımız değişkenlerin tanımlarını şöyle yapabiliriz.
colGPA: MSU GPA, Michigan State Üniversitesi not ortalaması
hsGPA: high school GPA, lise not ortalaması
ACT: ‘achievement’ score, ACT, bir öğrencinin okulda ne öğrendiğini ölçen bir başarı testidir. SAT daha çok bir yetenek testidir, muhakeme ve sözel yetenekleri test eder. Üniversiteler SAT veya ACT sonuçları ile öğrenci kabul eder.
Kitabınızda regresyon sonuçları direk verilen örneğin sonuçlarını bulmak isterseniz şu komutları kullanabilirsiniz.
coklureg <- lm(colGPA~ hsGPA+ACT,data = gpa1)
summary(coklureg)
##
## Call:
## lm(formula = colGPA ~ hsGPA + ACT, data = gpa1)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.85442 -0.24666 -0.02614 0.28127 0.85357
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 1.286328 0.340822 3.774 0.000238 ***
## hsGPA 0.453456 0.095813 4.733 5.42e-06 ***
## ACT 0.009426 0.010777 0.875 0.383297
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.3403 on 138 degrees of freedom
## Multiple R-squared: 0.1764, Adjusted R-squared: 0.1645
## F-statistic: 14.78 on 2 and 138 DF, p-value: 1.526e-06
Peki bu modeli nasıl yorumlayacağız? İlk olarak kesişim katsayısı, hsGPA ve ACT’nin her ikisi de sıfır olursa, öngörülen üniversite GPA’sini göstermektedir ve örneğimizde 1.29 olarak hesaplanmıştır. Üniversiteye giden hiç kimsenin lise not ortalaması sıfır veya başarı testi sıfır olmadığı için, bu denklemdeki kesişim kendi başına anlamlı değildir. Eğim katsayılarına bakınca ikisinin de bekleneceği gibi pozitif olduğunu görüyoruz. Eğer ACT puanını sabit tutarsak, hsGPA’deki 1 birimlik artış colGPA üzerinde 0.453 puanlık bir artış yaratacaktır. Başka bir deyişle, eğer ACT puanları aynı olan iki öğrenci varsa ve bir öğrencinin lise not ortalaması diğer öğrenciden bir puan yüksekse, bu öğrencinin üniversite not ortalamasının yarım puan daha fazla olmasını tahmin edebiliriz.
Üniversite not ortalamalarının 4 üzerinden, ACT sonuçlarının 36 puan üzerinden hesaplandığı düşünülürse, ACT’nin eğimi 0.0094’ün üniversite not ortalaması üzerinde fazla bir etkisi olmadığı düşünülebilir. Hata paylarını göz önüne aldığımızda ACT’nin sadece küçük değil aynı zamanda istatiksel olarak da anlamlı olmadığını göreceğiz.
Basit regresyon örneğimizi hatırlarsak
basitreg <- lm(colGPA~ACT,data = gpa1)
summary(basitreg)
##
## Call:
## lm(formula = colGPA ~ ACT, data = gpa1)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.85251 -0.25251 -0.04426 0.26400 0.89336
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 2.40298 0.26420 9.095 8.8e-16 ***
## ACT 0.02706 0.01086 2.491 0.0139 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.3656 on 139 degrees of freedom
## Multiple R-squared: 0.04275, Adjusted R-squared: 0.03586
## F-statistic: 6.207 on 1 and 139 DF, p-value: 0.0139
ACT’nin katsayısı çoklu regresyona göre bir hayli büyük kalıyor (0.02706/0.009426=2.87 kat daha fazla). ACT değerinin çoklu regresyonda lise not ortalaması eklenince azaldığını gözlemliyoruz. Çünkü lise not ortalaması ve ACT arasında yüksek bir korelasyon var. Bu durum bize aslında basit regresyon kullanıldığında temel varsayımı ihlal ettiğimize dair güçlü bir ipucu veriyor.
Bu örnekte son olarak basit ve iki bağımsız değişkenli regresyon grafiklerini gösterelim. Basit regresyon örneğimiz için, dağılım grafiğine bir regresyon çizgisi eklememizin yeterli olduğunu hatırlayalım.
plot(gpa1$ACT,gpa1$colGPA)
abline(basitreg)
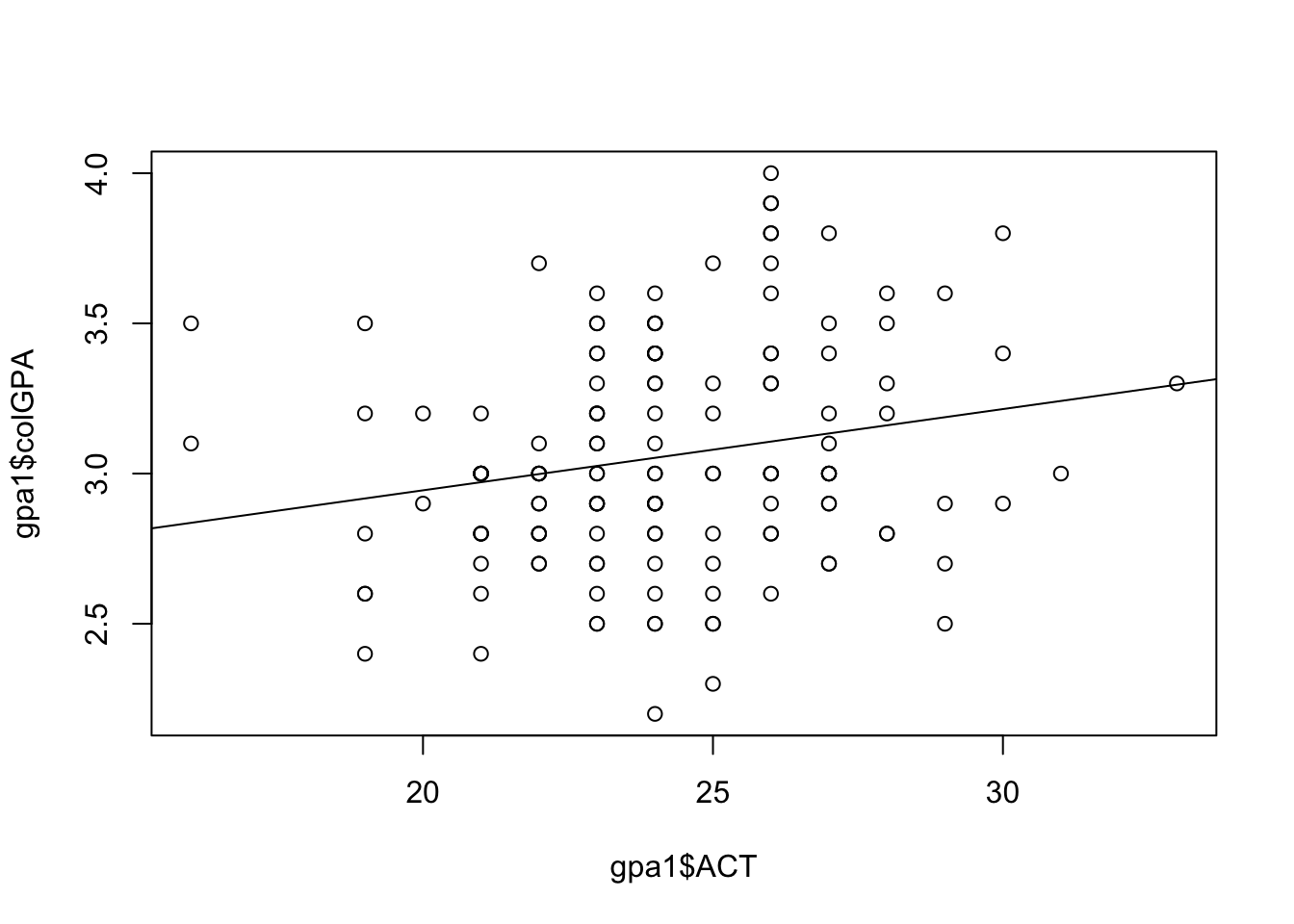 Bu grafik sadece iki boyutlu olduğundan, iki boyutlu bilgisayar ekranlarımızda göstermek daha kolaydır. Y eksenine üniversite not ortalaması, X eksenine ACT puanlarını koyuyoruz. Son olarak bulduğumuz eğim ve kesen katsayılarını grafiğimizde temsil eden doğrumuzu çiziyoruz.
Bu grafik sadece iki boyutlu olduğundan, iki boyutlu bilgisayar ekranlarımızda göstermek daha kolaydır. Y eksenine üniversite not ortalaması, X eksenine ACT puanlarını koyuyoruz. Son olarak bulduğumuz eğim ve kesen katsayılarını grafiğimizde temsil eden doğrumuzu çiziyoruz.
Ancak çok değişkenli regresyon grafiklerini, iki boyutlu bilgisayar ekranlarda göstermek biraz daha zor olabilir. En azından örneğimizdeki gibi üç boyutlu bir grafiğe ihtiyacımız var. Önce bütün değişkenler için üç boyutlu bir dağılım grafiği çizelim daha sonra doğru yerine bir düzlem eklememiz gerekecek.
library(plotly)
library(reshape2)
cf.mod <- coef(coklureg)
hsGPA <- seq(min(gpa1$hsGPA),max(gpa1$hsGPA),length.out=50)
ACT <- seq(min(gpa1$ACT),max(gpa1$ACT),length.out=50)
colGPA <- t(outer(hsGPA, ACT, function(x,y) cf.mod[1]+cf.mod[2]*x+cf.mod[3]*y))
p <- plot_ly(x=~hsGPA, y=~ACT, z=~colGPA,type="surface") %>%
add_trace(data=gpa1, x=gpa1$hsGPA, y=gpa1$ACT, z=gpa1$colGPA, mode="markers", type="scatter3d", opacity=0.5)
p
Üç boyutlu grafiğimiz olduğu için artık üzerine gidip sağa sola çevirebilirsiniz. Tahmin edebileceğiniz gibi üç boyutlu grafikleri algılamamız daha büyük boyutlu grafiklerden daha kolay. Şimdi bu noktalarda oluşacak hata payını minimize edecek bir düzleme ihtiyacımız var. Bunun için çoklu regresyonumuzdan yardım alacağız.
Sizin şimdilik bu grafikleri çizerken kullandığımız kodları anlamanıza gerek yok. Sadece grafiklerin şekline odaklanın. Bu grafik bize yapmış olduğumuz minimizasyon işleminin neden basit regresyona bir değişken daha eklediğimizde farklılaştığı ve ek değişkenin toplamda neden daha çok varyasyon açıklamaya yardım ettiği hakkında daha fazla bir içgüdü sunabilir.
Regresyon Tahmin Değerleri ve Hata Payı (OLS Fitted Values and Residuals)
Kitabınızdaki bu bölümde çoklu regresyonda tahmin değerleri ve hata payı üzerinde duruluyor. Tahmin değerlerini şapkayla (hat) gösteriyorduk.
Çoklu regresyon tahmin değerleri ve hata payının özellikleri.
- Hata payının örnek ortalaması sıfırdır, bu yüzden
- Hata payının herbir bağımsız değişkenle örnek kovaryası sıfırdır. Bu yüzden çoklu regresyon tahmin değerleri ve hata payı arasında örnek kovaryans da sıfırdır.
- Bütün bağımsız değişkenlerin ve bağımlı değişkenin ortalamaları regresyon çizgisi üzerindedir.
Çoklu Regresyon Modeli (Multiple Linear Regression (MLR) Model) Varsayımları
- Birinci Varsayım (MLR.1): Parametrelerde doğrusaldır.
- İkinci Varsayım (MLR.2): Rastgele Örnekleme.
Rastgele n örnek gözlemimiz var.
- Üçüncü Varsayım (MLR.3): Mükemmel bir eş doğrusallık yoktur.
Örneklemde (ve dolayısıyla popülasyonda), bağımsız değişkenlerin hiçbiri sabit değildir ve bağımsız değişkenler arasında kesin doğrusal ilişkiler yoktur.
- Dördüncü Varsayım (MLR.4): Sıfır koşullu ortalama.
Modelde bulunan bağımısız değişkenlerin herhangi bir değeri için hata payı
Gözlemlenemeyen Değişken Sapması (Omitted Variable Bias)
Gerçek popülasyon modelinde bulunan bir değişkeni modelimize eklememek gözlenemeyen değişken sapmasına yol açabilir. Bu sapmayı kitabınızda verilen örnek üzerinden inceleyeceğiz.
Varsayalım ki maaşları açıklayabilen sadece iki değişkene ihtiyacımız var. Bunlar eğitim ve yetenek. O zaman gerçek popülasyon modelimiz şu şekilde olur.
Bu modelin bütün çoklu regresyon varsayımlarını (MLR1-MLR4) sağladığını varsayalım. Şimdi yeteneği gözlemleyemediğinizi varsayalım ve sadece, eğitim ve maaş verilerine sahip olduğunuzu düşünün. Sadece basit regresyon modelini kullanabilirsiniz ve
Eğer
Burdan
Şimdi bu hesaplamamızı bir örnek üzerinden gösterelim. Bu örneği hatırlarsak
##install.packages("stargazer")
library(stargazer)
stargazer(list(coklureg,basitreg),type = "text")
##
## =================================================================
## Dependent variable:
## ---------------------------------------------
## colGPA
## (1) (2)
## -----------------------------------------------------------------
## hsGPA 0.453***
## (0.096)
##
## ACT 0.009 0.027**
## (0.011) (0.011)
##
## Constant 1.286*** 2.403***
## (0.341) (0.264)
##
## -----------------------------------------------------------------
## Observations 141 141
## R2 0.176 0.043
## Adjusted R2 0.164 0.036
## Residual Std. Error 0.340 (df = 138) 0.366 (df = 139)
## F Statistic 14.781*** (df = 2; 138) 6.207** (df = 1; 139)
## =================================================================
## Note: *p<0.1; **p<0.05; ***p<0.01
Çoklu regresyon modeli şu şekilde yazılabilir
Çoklu regresyon modelimiz gerçeğe daha yakın bir model olduğundan tahminleri şapkayla gösteriyoruz.
sapmareg<-lm(hsGPA~ACT,data = gpa1)
stargazer(list(sapmareg),type = "text")
##
## ===============================================
## Dependent variable:
## ---------------------------
## hsGPA
## -----------------------------------------------
## ACT 0.039***
## (0.009)
##
## Constant 2.463***
## (0.218)
##
## -----------------------------------------------
## Observations 141
## R2 0.120
## Adjusted R2 0.113
## Residual Std. Error 0.301 (df = 139)
## F Statistic 18.879*** (df = 1; 139)
## ===============================================
## Note: *p<0.1; **p<0.05; ***p<0.01
Regresyon sonucuyla bulduğumuz ve hesapladığımız
Çoklu regresyon (En küçük kareler (OLS)) tahmincilerinin varyansı
Homoskedastisite (Eş varyanslık), Çoklu eşdoğrusallık (Multicollinearity) ve Varyans enflasyon faktörü (Variance inflation factor (VIF))
Çoklu regresyonun 5. varsayımını hatırlayalım.
Beşinci Varsayım (MLR.5): Hata terimi
MLR.1 ila MLR.5 arasındaki varsayımlar topluca Gauss-Markov varsayımları olarak bilinir (kesitsel regresyon için).
Bir eğimin varyansını hesaplamak için şu formül kullanılabilir.
Bu formülle birlikte şu çıkarımları yapabiliriz.
Örneğimizi kullanarak bu parçaları çıkaralım.
standarthata<-summary(coklureg)$sigma
standarthata
## [1] 0.3403158
Standart hatayi hesaplamak için sadece sigma komutunu kullanıyoruz. Standart hatayi colGPA örneği için 0.34 olarak hesapladık.
sigmakare<-standarthata^2
sigmakare
## [1] 0.1158148
Regresörlerimiz arasındaki
Rjkare<-summary(sapmareg)$r.squared
Rjkare
## [1] 0.1195815
İki bağımsız değişkenimizin basit regresyonundan elde ettiğimiz
VIF<-1/(1-Rjkare)
VIF
## [1] 1.135823
son olarak n’i bulmalıyız.
n<-nobs(coklureg)
n
## [1] 141
son olarak
varxj<-var(gpa1$hsGPA)*(n-1)/n
varxj
## [1] 0.1016267
Şimdi formülümüzü kullanarak
varbetaj<-(1/n)*(sigmakare/varxj)*VIF
varbetaj
## [1] 0.009180115
sdbetaj<-varbetaj^0.5
sdbetaj
## [1] 0.09581292
Tablodan hsGPA’in standart hatasına bakarsanız bulduğumuz rakamla aynı olduğunu göreceksiniz.
VIF’i bulmanın kolay bir yolu car paketini yüklemektir.
require(car)
vif(coklureg)
## hsGPA ACT
## 1.135823 1.135823
require komutu paket yükleme komutu (install.packages) ve library komutunun ortak komutu olarak düşünülebilir. Eğer bir paketi daha önce yükleyip yüklemediğinizi hatırlamıyorsanız. require paket yüklenmemişse yükleyecek ve library() yapacaktır. Eğer daha önceden yüklüyse sadece library() yapacaktır. vif() komutu VIF’i regresyonunuz için otomatik olarak hesaplar. 1.1358’in bizim daha önce hesapladığımız VIF değeriyle aynı olduğuna dikkat edin.